Andrés Djordjalian - Indicart Carteles Electrónicos
(Volver a la página original)
Desenvolvimiento del método de los algoritmos genéticos (GA)
Una de las características de los algoritmos genéticos (quizás la más importante) es la robustez, es decir, el hecho de que un mismo algoritmo sirva para una gran variedad de problemas. Por eso es que nos ofrecen una alternativa para la optimización que demanda un mínimo conocimiento del dominio.
Es de suponer que no todos los problemas son igualmente aptos para ser resueltos por un GA. Una teoría que trate esto, que sería similar a lo que es la teoría de la complejidad para la teoría de algoritmos, es un campo de investigación aún inexplorado. Por ahora, el estado del arte en la investigación de los GA está en una temprana etapa de desarrollo de herramientas para evaluar la aptitud de un determinado GA para solucionar distintos tipos de problemas [For].
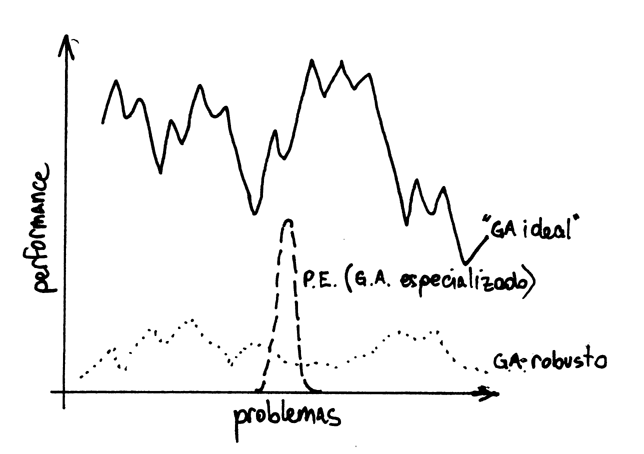
Podemos imaginarnos un diagrama en donde se grafique la performance, para distintos problemas, de un hipotético GA ideal. En el diagrama, el ideal variará según características de los problemas que aun no se comprenden del todo. Pero existe la importante "hipótesis de los bloques constructivos". "Bloques constructivos" son esquématas de bajo orden que tienen el poder de generar una mejora de aptitud en los cromosomas que los incluyen. La hipótesis dice que los GA son viables para resolver los problemas cuya solución pueda formarse con bloques constructivos. Por ejemplo, si el objetivo es encontrar la sarta de n bits con mayor cantidad de 1s, el problema parece ser muy apto para un GA ya que los bloques constructivos son los bits con valor igual a 1.
Donde existan técnicas para resolver problemas específicos, estas generalmente sobrepasarán a los GAs en velocidad y precisión. Por lo tanto, una de las areas de mayor interés para los GA son aquellos problemas para los que no se tiene suficiente información como para preparar un algoritmo más común. [Bea1]
Una aplicación que ejemplifica lo dicho en el párrafo anterior es pronosticar los mercados financieros, en donde un GA pondera los resultados entregados por distintas herramientas de análisis técnico de mercados según su relevancia para el mercado en cuestión. En este caso la información que no se posee es esa relevancia, y los GA sirven para analizarla.
Desenvolvimiento de los GA clásicos
En el diagrama anterior podemos agregar la performance de un GA diseñado para resolver una gran variedad de problemas, como es el GA clásico presentado por Holland. La performance del algoritmo será mucho menor al ideal y variará acompañando algunas variaciones de aquel, pero también tendrá areas de mayor o menor performance debidas a características intrínsecas a este algoritmo en particular.
Este hecho está relacionado con la conclusión del teorema de los esquemas [Hol], o en realidad con una versión generalizada de la misma: un GA va a tener una buena performance cuando los operadores que provoquen perturbaciones en los cromosomas (la cruza y la mutación) tengan una probabilidad de eliminar esquématas útiles ("probabilidad de disrupción") que sea adecuada.
La probabilidad de disrupción más adecuada será aquella que brinde el mejor balance entre exploración y explotación, condición que es deseable en todo método de optimización.
En el algoritmo clásico de Holland [Hol] si un esquema con buena performance tiene bits muy alejados (en la representación binaria con la que trabaja el algoritmo) la probabilidad de que la cruza los elimine es alta. Si los bits estuviesen juntos la probabilidad sería baja. El algoritmo va a tener mejor performance para aquellos problemas en donde la distancia entre bits dependa de la correlación de sus valores. Si esto no se cumple la performance del GA será pobre.
Este factor se debe al operador de cruza utilizado, no al método, y cambiándolo por uno independiente de la posición de los bits, como es la "cruza uniforme", se obtiene otro GA sin pérdida de performance para esos problemas. Mejor aún es la "cruza uniforme parametrizada", en donde la disrupción puede ser ajustada mediante un parámetro [Apéndice 1].
Podemos ver entonces que si priorizamos la robustez un importante area de investigación es el diseño de GAs que tengan cada vez mejor performance promedio.
Una técnica interesante para avanzar en este sentido es la utilización de operadores adaptativos. En estos hay distintos parámetros que se van ajustando en base al progreso que van produciendo en la población. Algunos candidatos para ser estos parámetros son: las probabilidades de los operadores de cruza y mutación, las posiciones de corte en la cruza de n-puntos y el tipo de operador utilizado.
Sin llegar a ser adaptativos los parámetros pueden ser dinámicos, es decir, cambiantes pero sin basarse en los resultados parciales. Por ejemplo, se puede comprobar que el efecto de la cruza va disminuyendo a medida que la población converge, por lo tanto una probabilidad de cruza que aumente con cada generación puede ser útil. [Bea2 (sección 9)]
La aplicación de los GA clásicos
La aplicabilidad de estos algoritmos super-robustos en la actualidad es limitada. El futuro es promisorio, ya que el avance de la teoría se verá acompañado por el los recursos computacionales, y gracias a su robustez estos GA podrían llegar a ser, además de una solución para problemas de los que sabemos poco, un medio para resolver problemas tras un mínimo análisis, o incluso una herramienta para realizar ese análisis.
Siguiendo esta filosofía, el GA ideal es aquel que sea lo mas eficiente y robusto posible. Para utilizarlo sería necesario aportar ciertos componentes dependientes del problema a resolver, y exteriores al algoritmo en sí:
Por ejemplo, si se quiere resolver el TSP (problema del viajante) la función aptitud que surge de inmediato es aquella que, al darle un camino de Hamilton, devuelve la distancia recorrida (varias suposiones mediante, como que el GA sea minimizador), y la representación más trivial es la codificación en binario de una serie de símbolos que indiquen las ciudades visitadas. En este caso, la restricción del dominio es el hecho de que una solución potencial, para poder ser procesada por la función aptitud, debe corresponder a un camino de Hamilton, y el problema antes mencionado se manifiesta en el hecho de que los operadores del GA pueden generar cromosomas que no lo hacen.
Otro ejemplo más simple es cuando usamos 4 bits para codificar una de 10 soluciones, ya que quedan 6 sartas que no corresponden a ninguna solución.
Manteniendo el enfoque de los GA clásicos, lo que se debe hacer para solucionar el problema es trabajar en la representación y en la función aptitud. Se han investigado varias formas de hacerlo:
Esta última afirmación se refuerza si tenemos en cuenta también el siguiente factor. En un GA la probabilidad de disrupción depende de los operadores que se utilicen, pero el valor más adecuado no se puede ajustar sin tener definido el problema a resolver (y la forma en que se codificarán las soluciones potenciales). Es muy difícil, entonces, conseguir una probabilidad de disrupción óptima. Solamente los operadores adaptativos podrían acercarse a ese ideal pero buenos operadores de este tipo no parecen ser simples y, de todas maneras, el mecanismo de adaptación siempre demandaría recursos.
La introducción de conocimientos sobre el problema en el GA
Si no priorizamos la robustez hay una manera evidente de solucionar el problema de las restricciones que es usar solamente operadores cerrados. Si al proveerles soluciones válidas la cruza y la mutación solo pueden generar soluciones también válidas, y se inicializa la población con cromosomas válidos en su totalidad, el problema antes mencionado se evita sin una pérdida de eficiencia.
Si nos damos permiso para adaptar los operadores podemos trabajar en tener una adecuada probabilidad de disrupción de la cruza y la mutación y maximizar el poder que tiene la cruza de combinar esquématas útiles, para mejorar aún más la performance.
Esto implica una filosofía distinta a la anterior: priorizar la eficiencia por sobre la robustez, sugieriendo reformular el GA de acuerdo al problema en lugar de hacerlo al revés, como antes.
Otra posibilidad que tenemos, dentro de esta filosofía, es la de incorporar heurísticas, por ejemplo, inicializando el algoritmo con cromosomas que puedan ser relativamente buenos, en lugar de elegirlos al azar, o agregando operadores que mejoren las soluciones en base a conocimientos que tengamos sobre el problema. Por ejemplo, en un TSP plano se sabe que una solución óptima no tiene cruces, entonces un operador de "descruce" podría serle aplicado a un porcentaje de la población en cada iteración.
En el diagrama de problema/performance del principio podríamos graficar las curvas correspondientes a estos nuevos algoritmos. Estas serían bajas pero con picos que llegarían más alto que la de los GA super-robustos, buscando el punto máximo dado por la curva ideal. Los picos de las distintas curvas podrían tener diferentes amplitudes, dependiendo del grado de especialización de su correspondiente algoritmo.
Por razones históricas, para los métodos que incorporan a un GA conocimientos sobre el dominio se usa frecuentemente la palabra "evolutivos" mientras que el vocablo "genéticos" se reserva para los relacionados con los GA super-robustos explicados con anterioridad. Quizás en un afán de independizarse de motivos ajenos a la teoría, Michaelewicz, al igual que otros, sugiere que los "algoritmos genéticos" son una clase de "algoritmos evolutivos" (la clase de los que utilizan operadores robustos) pero el título de su libro "Algoritmos genéticos + estructuras de datos = programas evolutivos" parece más cercano a la nomenclatura dictada por la historia [Mic]. Muchos otros denomiman "algoritmos genéticos" al conjunto de la teoría. Mi opinión es que la jerarquía de los algoritmos genéticos o evolutivos necesita pulirse, y seguramente lo hará con el tiempo. [Spe93a (sección 2)] [Spe93b (sección 2)]
Las ventajas de los programas evolutivos (EP), que son la solución del problema de las restricciones y la utilización de operadores más eficientes, están intimamente relacionadas con la representación que se use para las soluciones potenciales. Si el programa se ejecuta en una computadora digital los cromosomas siempre van a ser secuencias de bits, pero los operadores genéticos que se utilicen (que van a estar adaptados al problema) van a depender de la abstracción que se esté usando para codificar las soluciones en bits.
Como ejemplo pensemos en un problema de optimización numérica que usa números codificados en coma flotante. En un operador de cruza adecuado para este problema se podría preferir promediar números en lugar de combinar sus bits, y hacerlo con la mantisa y el exponente por separado. En el EP se podría dejar de mencionar el hecho de que la representación es en coma-flotante, pero entonces los operadores parecerían arbitrarios. Darle a la representación caracter de parámetro es útil para incorporar semántica en los operadores. Entonces podemos decir que un EP trabaja con valores en coma-flotante, o con vectores, matrices, listas, etc. En realidad solo estamos indicando algunas características de los operadores. Es interesante cuando las representaciones son autómatas o programas LISP, dando lugar a la "programación genética" o "programación evolutiva".
Descripción de un programa evolutivo para resolver el TSP
En esta sección se aplicará lo dicho hasta ahora para diseñar un EP que resuelva el TSP [Mic]. El algoritmo utilizará la arquitectura clásica, con los operadores adaptados especialmente según se indicará. Empezamos por indicar la representación, que servirá como herramienta para interpretar los operadores.
Conclusiones
Se presentaron dos rumbos distintos en el desarrollo de la teoría de la computación evolutiva. Estos pueden ser complementados, por ejemplo en algoritmos robustos que incluyen la posibilidad de elegir la representación y otros parámetros.
Los algoritmos genéticos (super-robustos) prometen convertirse en un medio de resolución de problemas de lo que sabemos poco y como una alternativa de diseño de algoritmos. También tienen potencial como herramienta de análisis de problemas. Por otra parte, la robustez permite un desarrollo de teoría que en los no-robustos se dificulta.
Los algoritmos evolutivos menos-robustos pueden resolver ciertos problemas en forma (hoy en día) práctica. La intención de este trabajo fue introducir el tema y sugerir unos pocos criterios aplicables al diseño y a la utilización de tales algoritmos.
Mi conclusión, después de estudiar esta teoría y hacer este trabajo, es que esta area promete ser una fuente de herramientas dentro de la algoritmia pero que actualmente hay mucho por hacer. Por otro lado, me parece importante complementar esta teoría con datos empíricos, para comprender mejor su alcance.
Apéndices
Apéndice 1 - Cruza uniforme estándar y parametrizada
La cruza uniforme opera sobre copias de los padres, en donde para cada gen se elige, al azar, si intercambiarlos o no.
ej. Padres: 11111111 y 00000000
Decisión de intercambiar bits para cada posición: 0 no,
1 sí, 2 sí, 3 sí, 4 no, 5 sí, 6 sí,
7 no
Hijos: 10001001 y 01110110
En la cruza uniforme estándar la probabilidad de intercambiar cada gen es de 0,5. En la parametrizada su valor es un parámetro; esto permite ajustar la disrupción, porque una menor probabilidad significa menor disrupción. [Spe91]
Apéndice 2 - Selección proporcional a la aptitud vs. selección proporcional al orden
El mecanismo de selección proporcional a la aptitud, propuesto por Holland [Hol], es sensible a la escala de la función objetivo. Si la función asigna a los buenos candidatos valores mucho más altos que los que le asigna a los medianamente buenos, los primeros van a ocupar rapidamente la totalidad de la población a pesar de que los segundos tenían características interesantes para aportar en la búsqueda de un óptimo. En otras palabras, se pierde variedad genética. Incluso la población puede llegar a ser ocupada totalmente por un candidato muy mejorable. Esta última situación es una patología frecuente en los GA que se denomina "convergencia anticipada".
Estos problemas se pueden solucionar mediante una selección como la proporcional al orden. En esta, la repetición de los candidatos está dada por su número de orden si los tomamos ordenados según su aptitud. Así se consigue una independencia de la escala aunque, seguramente, a expensas de tiempo de procesamiento ya que una cierta información de la aptitud se pierde en el proceso. [Spe93a (sección 3.1)]
Referencias
[Bea1] D. Beasley, D. Bull, R. Martin: An Overview of Genetic Algorithms. Part One - Fundamentals (University Computing, 1993, 15(2), 58-69) (OVER93_P.GZ)
[Bea2] D. Beasley, D. Bull, R. Martin: An Overview of Genetic Algorithms. Part Two - Research Topics (University Computing, 1993, 15(4), 170-181) (OVER93-2.GZ)
[For] S. Forrest, M. Mitchell: What Makes a Problem Hard for a Genetic Algorithm? Some Anomalous Results and Their Explanation (FORREST-.PS)
[Hol] J. H. Holland: Adaptation in Natural and Artificial Systems
[Mic] Z. Michalewicz: Genetic Algorithms + Data Structures = Evolution Programs, Springer-Verlag
[Spe91] W. Spears, K. De Jong: On the Virtues of Parameterized Uniform Crossover (ICGA91_P.GZ)
[Spe93a] W. Spears, K. De Jong, T. Back, D. Fogel, H. Garis: An Overview of Evolutionary Computation (Proceeding of the 1993 European Conference on Machine Learning) (ECML93_P.GZ)
[Spe93b] W. Spears, K. De Jong: On the State of Evolutionary Computation (ICGA93_P.GZ)
NOTA: Los papers de esta lista fueron sacados de Internet. Entre paréntesis están los nombres de los archivos, todos en postscript, aunque hay que tener en cuenta que algunos están acortados por haberlos pasado de UNIX a DOS. Los papers pueden ser encontrados en la red pero, para facilitar las cosas, voy a tratar de ponerlos en una página en http://www.indicart.com.ar/ga/ junto con más material.